
成功案例
CASE
咨询电话
400-123-4567
手 机:13988999988
电 话:400-123-4567
传 真:+86-123-4567
邮 箱:[email protected]
地 址:广东省广州市天河区88号
电 话:400-123-4567
传 真:+86-123-4567
邮 箱:[email protected]
地 址:广东省广州市天河区88号

微信扫一扫
DeepSeekr1的幻觉速率最多降低了50%,用户说他们
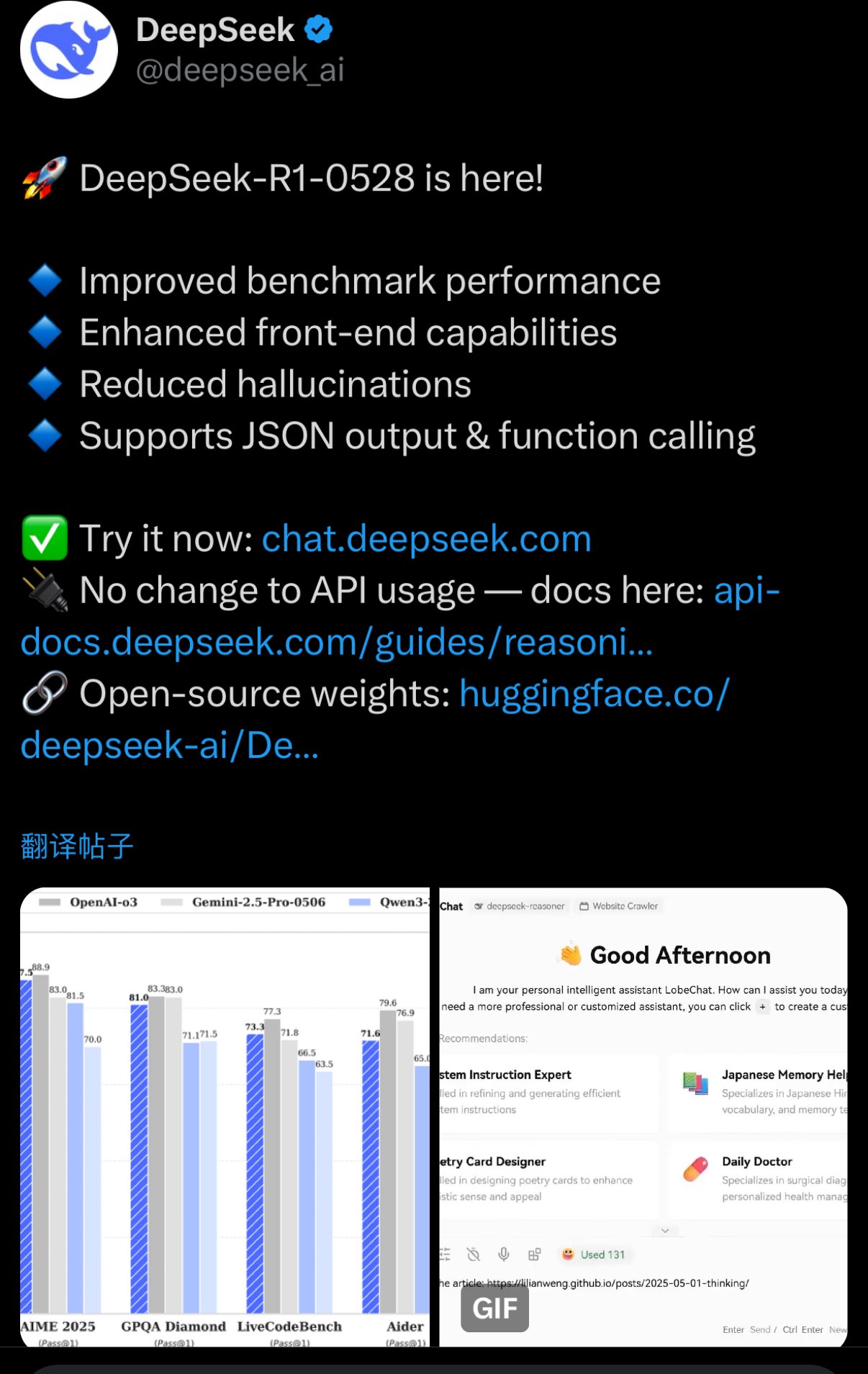 在5月29日晚上的“ Hug”上启动了R1模型更新后,DeepSeek终于发表了正式公告,在此版本中介绍了某些特征的详细信息,包括增强深思熟虑技巧,改善幻觉和改善创意写作。从评估数据的角度来看,官员们说,更新的R1模型在包括数学,编程和一般逻辑在内的所有参考评估中都取得了所有国家模型的最佳结果,并且与其他一般绩效的其他国际模型,例如O3和Gemini-2.5-Pro。值得一提的是,DePseek提到,DeepSeek R1的新版本已针对“幻觉”的问题进行了优化。与以前的版本相比,更新的模型可以将幻觉率降低约45%-50%,例如重写和抛光,摘要和阅读理解,从而更加精确和更精确可靠的结果。 SO称为幻觉是大型模型的“胡说八道”。 DeepSeek的幻觉率并不较低,并且已经由许多用户和开发人员讨论。 5月15日,Superclue为中国大型模型发布了最后一轮忠实的幻觉评估结果,表明先前的DeepSeek-R1模型的幻觉速度约为21%,在评估的国家模型中分类了第五。根据SuperClue的说法,推理模型中的幻觉比非参与模型中的幻觉更为重要。在评估中,推理模型的平均幻觉率为22.95%,非倾斜模型的平均幻觉率为13.52%。除了改善幻觉之外,我还表现出来表明,在复杂的推理任务中,新的R1模型的性能显着改善。例如,在AIME 2025测试中(CA的数学参考点模型可以从数学上推断),新模型的精度从上一个版本增加到了87.5%。此外,更新后的R1模型对有争议的论文,小说,散文和其他流派进行了更优化,这使其能够以更完整的长度和结构进行更长的工作,同时呈现靠近人类偏好的写作风格。在官方版本之前,许多证据表明,新的R1模型中代码的功能有了显着改善。在测试平台上的实时代码库中的代码,其性能几乎与Openai重量级的O3高模型相媲美。官方公告还确定,在前端代码(角色游戏)的生成等领域,模型的特征已被更新和改进。在迭代路线中,DeepSeek-R1-0528使用2024年12月推出的V3 DeepSeek基地作为基础,但在此前投资了更多的计算机功能ER训练,大大改善了思想和模型推理能力的深度。该R1的新模型参数为685B,开源版本的上下文长度为128K(网页,API)提供了64K上下文。同时,根据R1的较旧版本,该开源模型的重量仍然首先集成,采用了MIT许可证,从而使用户可以使用模型输出并通过模型的蒸馏来训练其他模型。有趣的是,在X平台上的“ DeepSeek官方评论”部分中,讨论的所有主题涉及R2“ ERE R2(需要R2模型)”。该行业长期以来一直在等待下一代DeepSeek模型。根据DeepSeek的更新,一些用户推测:“这是否意味着您暂时尚未听说过R2?”一些用户开玩笑说该模型可能是开发中的R2,但是当它变成R1时。
在5月29日晚上的“ Hug”上启动了R1模型更新后,DeepSeek终于发表了正式公告,在此版本中介绍了某些特征的详细信息,包括增强深思熟虑技巧,改善幻觉和改善创意写作。从评估数据的角度来看,官员们说,更新的R1模型在包括数学,编程和一般逻辑在内的所有参考评估中都取得了所有国家模型的最佳结果,并且与其他一般绩效的其他国际模型,例如O3和Gemini-2.5-Pro。值得一提的是,DePseek提到,DeepSeek R1的新版本已针对“幻觉”的问题进行了优化。与以前的版本相比,更新的模型可以将幻觉率降低约45%-50%,例如重写和抛光,摘要和阅读理解,从而更加精确和更精确可靠的结果。 SO称为幻觉是大型模型的“胡说八道”。 DeepSeek的幻觉率并不较低,并且已经由许多用户和开发人员讨论。 5月15日,Superclue为中国大型模型发布了最后一轮忠实的幻觉评估结果,表明先前的DeepSeek-R1模型的幻觉速度约为21%,在评估的国家模型中分类了第五。根据SuperClue的说法,推理模型中的幻觉比非参与模型中的幻觉更为重要。在评估中,推理模型的平均幻觉率为22.95%,非倾斜模型的平均幻觉率为13.52%。除了改善幻觉之外,我还表现出来表明,在复杂的推理任务中,新的R1模型的性能显着改善。例如,在AIME 2025测试中(CA的数学参考点模型可以从数学上推断),新模型的精度从上一个版本增加到了87.5%。此外,更新后的R1模型对有争议的论文,小说,散文和其他流派进行了更优化,这使其能够以更完整的长度和结构进行更长的工作,同时呈现靠近人类偏好的写作风格。在官方版本之前,许多证据表明,新的R1模型中代码的功能有了显着改善。在测试平台上的实时代码库中的代码,其性能几乎与Openai重量级的O3高模型相媲美。官方公告还确定,在前端代码(角色游戏)的生成等领域,模型的特征已被更新和改进。在迭代路线中,DeepSeek-R1-0528使用2024年12月推出的V3 DeepSeek基地作为基础,但在此前投资了更多的计算机功能ER训练,大大改善了思想和模型推理能力的深度。该R1的新模型参数为685B,开源版本的上下文长度为128K(网页,API)提供了64K上下文。同时,根据R1的较旧版本,该开源模型的重量仍然首先集成,采用了MIT许可证,从而使用户可以使用模型输出并通过模型的蒸馏来训练其他模型。有趣的是,在X平台上的“ DeepSeek官方评论”部分中,讨论的所有主题涉及R2“ ERE R2(需要R2模型)”。该行业长期以来一直在等待下一代DeepSeek模型。根据DeepSeek的更新,一些用户推测:“这是否意味着您暂时尚未听说过R2?”一些用户开玩笑说该模型可能是开发中的R2,但是当它变成R1时。相关产品

